Welcome!

I’m a recent graduate of Berkeley EECS, where I was fortunate to be advised by Dawn Song and Ruoxi Jia.
Before Berkeley, I spent 3 years in industry, where I independently launched deep learning and classical machine learning programs to capture high-value opportunities.
My research interests are primarily in deep learning, reinforcement learning (RL), and unsupervised learning. I also have experience in computer vision, robotics, optimization, and natural language processing.
I enjoy developing machine learning algorithms as well as software and systems that accelerate these algorithms. Outside of work, I like biking, playing tennis, and hanging out with cats (though dogs are a very close second).
Education

University of California, Berkeley
Master’s in Electrical Engineering and Computer Science
GRE: 170/170 Quant, 169/170 Verbal (99.9th percentile)
Selected coursework

Experience
Academic




Complex Skill Acquisition through Simple Skill Imitation Learning
Author: Me
Topics: reinforcement learning, deep learning, unsupervised learning
Humans have the power to reason about complex tasks as combinations of simpler, interpretable subtasks. There are many hierarchical reinforcement learning approaches designed to handle tasks comprised of sequential subtasks, but what if a task is made up of concurrent subtasks?
We propose a novel objective function that regularizes a version of the VAE objective in order to induce latent space structure that captures the relationship between a behavior and the subskills that comprise this behavior in a disentangled and interpretable way. We evaluate both the original and new objectives on a moderately complex imitation learning problem from the DeepMimic library, in which agents are trained to perform a behavior after being trained on subskills that qualitatively comprise that behavior.
Keywords: hierarchical imitation learning, adversarial imitation learning, generative models, autoregressive models, mutual information maximization
Lagrangian Duality in Reinforcement Learning
Author: Me
Topics: reinforcement learning, optimization
Though duality is used extensively in certain fields, such as supervised learning in machine learning, it has been much less explored in others, such as reinforcement learning. In this paper, we show how duality is involved in a variety of RL work, from that which spearheaded the field (e.g. Richard Bellman’s tabular value iteration) to that which has been put forth within just the past few years yet has already had significant impact (e.g. TRPO, A3C, GAIL).
We show that duality is not uncommon in reinforcement learning, especially when value iteration, or dynamic programming, is used or when first or second order approximations are made to transform initially intractable problems into tractable convex programs.
In some cases duality is used as a theoretical tool to prove certain results or to gain insight into the meaning of the problem involved. In other cases duality is leveraged to employ gradient-based methods over some dual space, as is done in alternating direction method of multipliers (ADMM), mirror descent, and dual averaging.
Keywords: duality, optimization, mirror descent, dual averaging, alternating method of multipliers (ADMM), value iteration, trust region policy optimization (TRPO), asynchronous actor critic (A3C), generative adversarial imitation learning (GAIL)
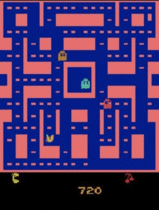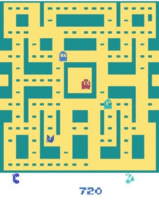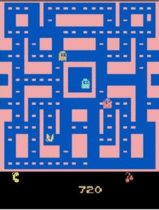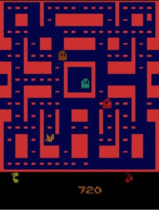
Negative Interference in Multi-Task Reinforcement Learning due to Pixel Observation Space Differences
Author: Me | Thanks to Pieter Abbeel for proposing the base experiment design!
Results Data Visualization Code
Topics: reinforcement learning, deep learning, distributed systems, parallel computing
Transfer learning has revolutionized certain fields, such as computer vision and natural language processing, but reinforcement learning has not yet seen similar benefit. One reason is that RL tasks are generally more specific than images or sentences are. Namely, some ways that tasks differ are in states, actions, reward schemes, and temporal horizons.
To better understand how different raw pixel state distributions affect multi-task reinforcement learning, we evaluate multi-task policies on a set of tasks that differ only in state distribution. In this work we focus on how the DQN architecture and some of its variants handle multi-task learning of Atari games that differ only in raw pixel observation space.
Keywords: multi-task reinforcement learning, transfer learning, generalization, DQN, parallel computing

Robust Detection of Manipulated Videos (i.e. Deepfakes)
Authors: Me, Ujjwal Singhania, Yijiu Zhong | Thanks to Dawn Song and Ruoxi Jia for advising this work!
Topics: computer vision, deep learning, image processing
Artificial videos are becoming indistinguishable from real content. For example, videos of world leaders have been manipulated to make them appear to say incendiary things. Previous approaches have failed to generalize over varied deepfake generation methods. We use machine learning and computer vision to create a classifier that detects deepfake videos and is robust to unseen manipulation methods.
Keywords: deepfake detection, robustness, generalization, Deepfake Detection Challenge (DFDC), optical flow, Face X-ray, EfficientNet
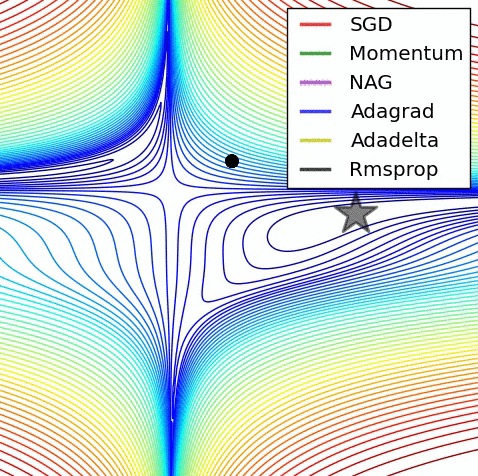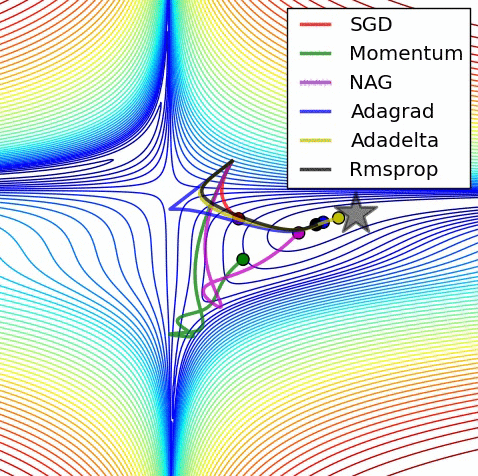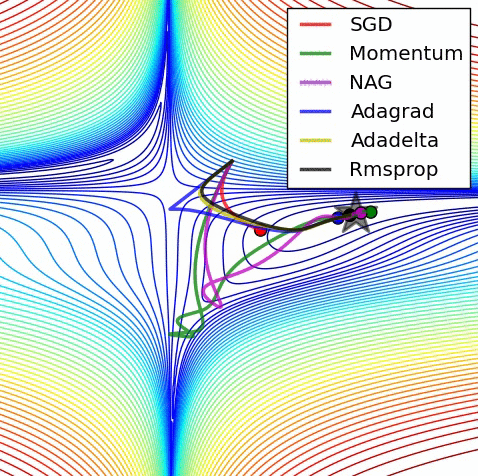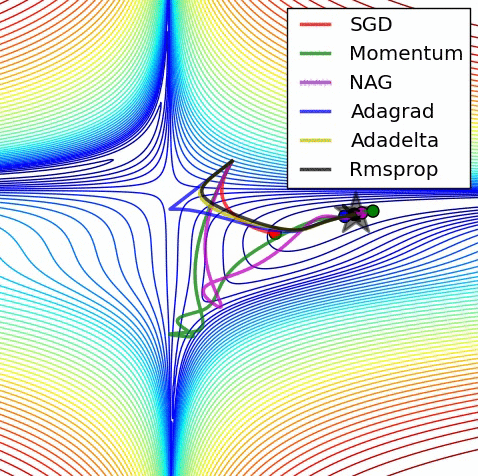 Image adapted from Alec Radford
Image adapted from Alec Radford
LipGD: Faster Gradient Descent through Efficient Lipschitz Constant Approximations
Author: Me
Topics: optimization, deep learning
Optimization theory gives us nice guarantees on the optimality and convergence rates of convex problems. A quantity of particular interest is the Lipschitz constant of the derivative of the function being optimized. The reciprocal of this quantity upper bounds the step size of the gradient update.
Unfortunately, most problems of interest are highly non-convex, so such guarantees don’t directly apply. However, we see empirically that there generally exists a neighborhood around any given iterate of parameter values that is convex, and such guarantees do directly apply within this neighborhood. We also see empirically that the Lipschitzness of the gradient doesn’t change much from iterate to iterate. We use this information to safely take gradient steps that are larger than those dictated by common step size schedules, leading to faster convergence.
Certain problems, such as those involving adversarial training (e.g. Wasserstein GAN), advocate momentum-free optimization, which has much slower convergence than momentum-based optimization. We believe that our approach could be especially useful in addressing these problems.
Keywords: Lipschitz, smoothness, stochastic gradient descent, non-convex optimization, momentum-free optimization, Wasserstein GAN (WGAN)

Improving Multi-Task Reinforcement Learning through Disentangled Representation Learning
Author: Me
Topics: reinforcement learning, unsupervised learning, deep learning
When humans learn to perform a task, they tend to also improve their skills on related tasks, even without explicitly practicing these other tasks. In reinforcement learning (RL), the multi-task setting aims to leverage similarities across tasks to help agents more quickly learn multiple tasks simultaneously. However, multitask RL has a number of key issues, such as negative interference, that make it difficult to implement in practice.
We propose an approach that learns disentangled representations in order to alleviate these issues and find effective multi-task policies in a high-dimensional raw-pixel observation space. We show that this approach can be superior to other multi-task RL techniques with little additional cost. We also investigate disentanglement itself by capturing, adjusting, and reconstructing latent representations that have been learned from Atari images and gain insight into their underlying meaning.
Keywords: multi-task reinforcement learning, disentanglement, representation learning, variational autoencoder, DQN

Empirical Evaluation of Double DQN under Monotonic Reward Transformations
Author: Me
Topics: reinforcement learning, deep learning
Several tricks are employed to get DQNs to learn favorable policies. One of these is the use of reward clipping, in which rewards obtained by the agent are clipped to the interval [-1, +1] from their original value. Though some Atari games, such as Pong have only reward values that fall within this interval, most Atari games have no reward values within this interval. One stark example is Battlezone, in which the smallest reward and finest granularity of reward are both 1000.
For tasks with rewards primarily outside of [-1, +1], clipping rewards to this interval qualitatively changes the objective maximized by DQN to the frequency of rewards rather than the quantity of overall reward. In some cases these two correlate well, and performance may not be affected much by using clipped versus unclipped rewards. However, it’s easy to find tasks in which this invariance does not hold. In this work we propose three carefully chosen reward transformations and explore the performance of Double DQN under each of these as well as under the de facto reward clipping transformation.
Keywords: DQN, reward shaping
 Image adapted from John Schulman
Image adapted from John Schulman
TrajOpt Presentation
Author: Me, Eugene Vinitsky
Topics: robotics, optimization
TrajOpt is a trust region optimization-based motion planning algorithm that tends to produce high-quality trajectories more quickly and reliably than the leading motion planning algorithms at the time of its inception, such as CHOMP, do.
We give a 30 minute talk on TrajOpt, covering the state of motion planning at the time, the TrajOpt algorithm, its key ideas, a detailed comparison between TrajOpt and CHOMP, and its shortcomings. We also lead a discussion on building upon TrajOpt and on addressing its issues.
Keywords: trajectory optimization, motion planning, trust region method, collision checking

Variational Autoencoder (VAE) Viewer
Author: Me
Topics: unsupervised learning, deep learning
A portable implementation of variational autoencoders (and some variants). This tool can be used to quickly view learned latent representations of user-provided images.
Keywords: (beta) variational autoencoder, representation learning
Industry

Shell Oil Company
Deep Learning Research Engineer (Enhanced Problem Solving Engineer)
Led small, high-impact teams to investigate and capture high-value (i.e. $10+ million) opportunities across North America. Collaborated with researchers around the world. Attained record-breaking product yield.
Initiated the use of deep learning and statistical modeling to evaluate and make predictions on large sets of noisy data. Proposed and implemented data-driven solutions that resolved long-standing issues in difficult environments.
Machine Learning Engineer (Electrical Engineer)
Launched the first deep learning and statistical machine learning equipment management programs. Developed software that cleaned and visualized data, trained machine learning models, and made accurate predictions on complex data. Supervised up to 14 technical personnel concurrently in safety-critical environments.
Service
Reviewer for NeurIPS 2020, ICML 2020
Designed a biogas plant to supply clean, renewable energy to villagers in rural India Video